2.1 Introduction to the Data Science Lifecycle
📊 2.1 Introduction to the Data Science Lifecycle
Data science is a multidisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. The data science lifecycle refers to a series of iterative steps that data scientists follow to uncover meaningful insights from data, and ultimately, make informed decisions. Understanding the data science lifecycle is critical as it provides a structured approach to solving data-driven problems.
🔍 Overview of the Data Science Lifecycle
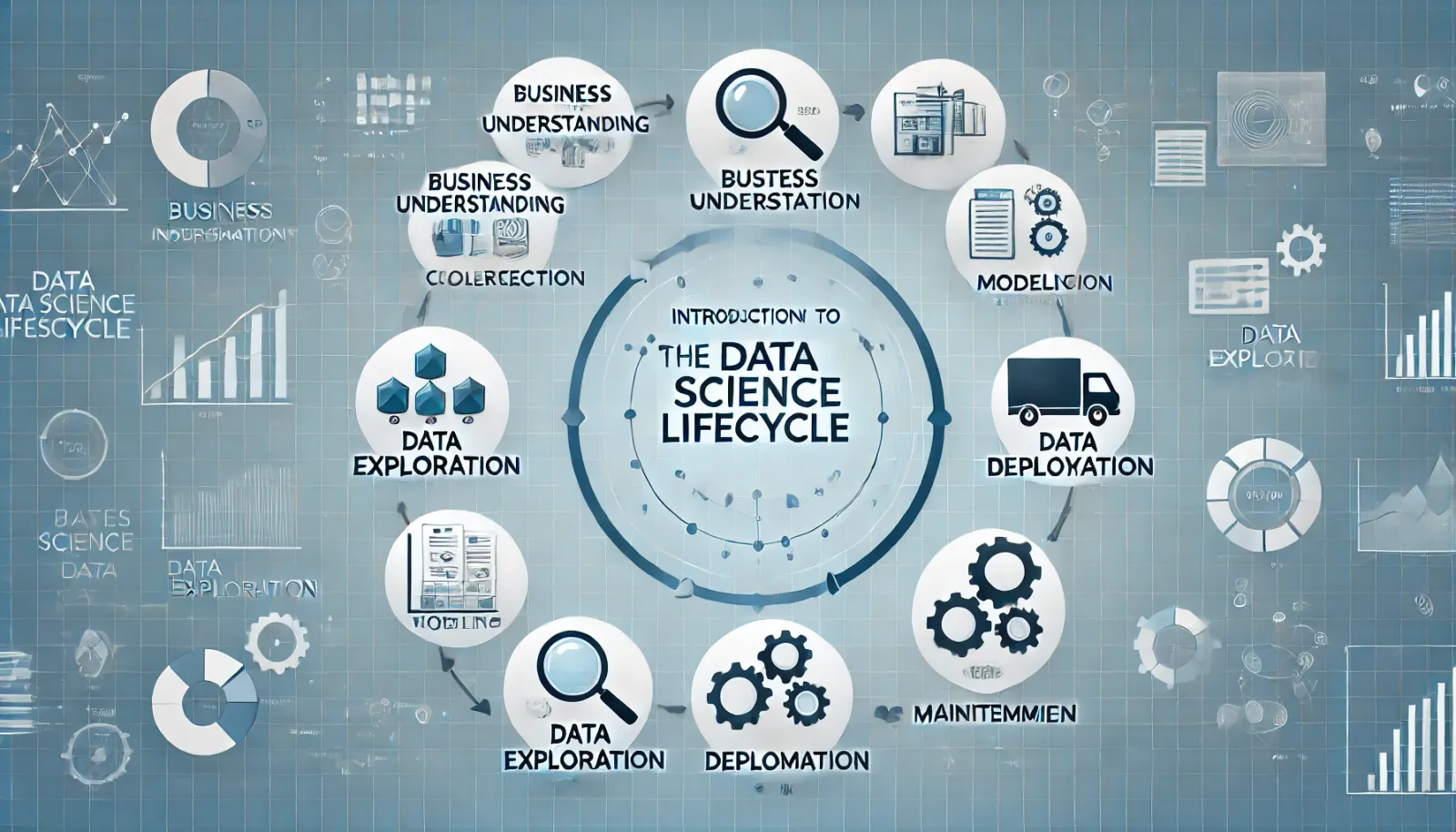
The data science lifecycle encompasses various stages that guide data scientists through the process of working with data. These stages typically include:
- 1. Business Understanding: In this first stage, the focus is on understanding the problem at hand. What are the business objectives? What challenges are the stakeholders facing? This is the most critical step as it defines the goals for the data science project.
- 2. Data Collection: Once the problem is well understood, the next step involves gathering the data. This could include internal company data, data from public databases, or even scraping data from web sources. The quality of the data collected here will directly affect the accuracy of the model built later.
- 3. Data Preparation: Data is rarely perfect. This stage involves cleaning the data, handling missing values, normalizing or transforming variables, and preparing it for analysis. It's one of the most time-consuming parts of the data science lifecycle.
- 4. Data Exploration: At this stage, data scientists dive deep into the data to explore patterns, trends, and anomalies. Visualizations such as histograms, scatter plots, and correlation matrices are used to understand the relationships between variables.
- 5. Modeling: Once the data is prepped and understood, the next step is building models to solve the problem. This could involve machine learning algorithms, regression models, or other statistical techniques to predict outcomes, classify data, or find clusters.
- 6. Evaluation: In this stage, data scientists assess how well their models perform. This could involve accuracy scores, precision, recall, or other performance metrics. Based on the evaluation, they may decide to refine their model or experiment with different algorithms.
- 7. Deployment: Once a model is proven to perform well, it is deployed into production. This might involve integrating the model with existing business systems or deploying it as part of a cloud service. Monitoring the model's performance over time is key at this stage.
- 8. Maintenance: Data science is not a one-time process. After deployment, the model must be maintained and monitored for performance degradation, new data inputs, and business changes. This ensures the model remains accurate and relevant over time.
📂 Key Stages of the Data Science Lifecycle Explained
1. Business Understanding
The foundation of any data science project begins with a clear understanding of the business problem. This stage focuses on defining the project’s objectives, identifying the problem statement, and determining the scope of work. Without a clear understanding of what the business needs, a data science project can easily become unfocused or misguided. Data scientists collaborate closely with stakeholders to ask the right questions and translate business objectives into data problems.
2. Data Collection
After the business goals are defined, the next step is to gather the necessary data. This stage involves identifying the right data sources, which can come from databases, APIs, surveys, or third-party datasets. The accuracy and completeness of the data collected will have a direct impact on the project's success. Data collection can also involve data wrangling, where raw data is cleaned and structured to make it usable.
3. Data Preparation
Data is rarely perfect when first collected. Data preparation is one of the most critical steps, as it ensures that the data is in the right format for analysis. This process may include removing duplicates, handling missing values, encoding categorical variables, and normalizing numeric variables. This stage often takes the most time and effort, as the quality of the data determines the quality of the results.
4. Data Exploration
Data exploration allows data scientists to dive deeper into the dataset and understand patterns, trends, and relationships. Exploratory Data Analysis (EDA) techniques such as plotting graphs, generating summary statistics, and examining correlations help to uncover hidden insights. This step is crucial for identifying features that can be used in the modeling stage and for gaining a thorough understanding of the data.
5. Modeling
The modeling stage is where the real magic happens. Using various algorithms, data scientists build models that aim to predict outcomes, classify data, or segment groups. Popular techniques include linear regression, decision trees, random forests, and neural networks. Model selection depends on the type of problem, the nature of the data, and the business objective. Data scientists also tune their models to achieve optimal performance.
6. Evaluation
After the model is built, it must be evaluated to ensure it meets the project’s objectives. Performance metrics such as accuracy, precision, recall, and F1 scores help to assess how well the model is performing. If the model doesn't meet the desired performance, further iterations may be necessary. Evaluating models thoroughly before deployment helps avoid issues when scaling the solution to production environments.
7. Deployment
Once the model performs well in the evaluation phase, it’s time to deploy it. This could involve integrating the model into a company’s decision-making process, embedding it into an application, or exposing it via an API. In production, the model needs to be monitored and maintained to ensure it continues to perform well as new data flows in and business environments evolve.
8. Maintenance
A data science project doesn’t end with deployment. Ongoing monitoring and maintenance are necessary to ensure the model remains relevant and performs optimally. As new data is collected, the model may need retraining or updating. Additionally, business needs and objectives can change, requiring adjustments to the original model.
🔍 Conclusion
The data science lifecycle is an iterative process that ensures data scientists can derive meaningful insights and actionable solutions from data. By understanding and following the lifecycle’s steps—business understanding, data collection, data preparation, exploration, modeling, evaluation, deployment, and maintenance—data scientists can ensure that their models provide value to stakeholders and contribute to solving real-world problems.